Save time with the right BibFox strictness setting
You run BibFox on 30 references and 12 come back with an orange warning. Most are fine. One actually needed attention.
Switching to Medium strictness would have sent you only four orange references instead. The strictness setting controls how much evidence the algorithm requires before it clears a reference automatically. The right setting depends on what you are doing with the results.
This post walks through the two presets, when each one fits, and when custom strictness makes sense.
What you'll learn
- What the strictness setting does to your orange pile
- When to use the High preset (95%) and when Medium (70%) is the better choice
- When to set a custom value — and what precision you give up
- How BibFox ensures quality at low strictness
Jump to what matters most
- What the strictness setting controls
- High vs. Medium: which fits your use case
- Custom strictness: when the presets don't fit
- How the algorithm makes low strictness work
Check your own reference list
Run BibFox on your sources and review the evidence yourself.
What the strictness setting controls
The strictness setting is an evidence threshold. At 95%, the algorithm requires a close match across several fields before it clears a reference as validated. A small discrepancy — a slightly different title, a mismatched year — is enough to send it back as an orange warning. At 70%, the threshold is lower, so references with minor variations are more likely to clear automatically.
This creates a direct tradeoff between precision and what BibFox calls the degree of automation — the share of your list that does not come back orange.
The chart below shows the full picture across the range from 100% down to 40% strictness:
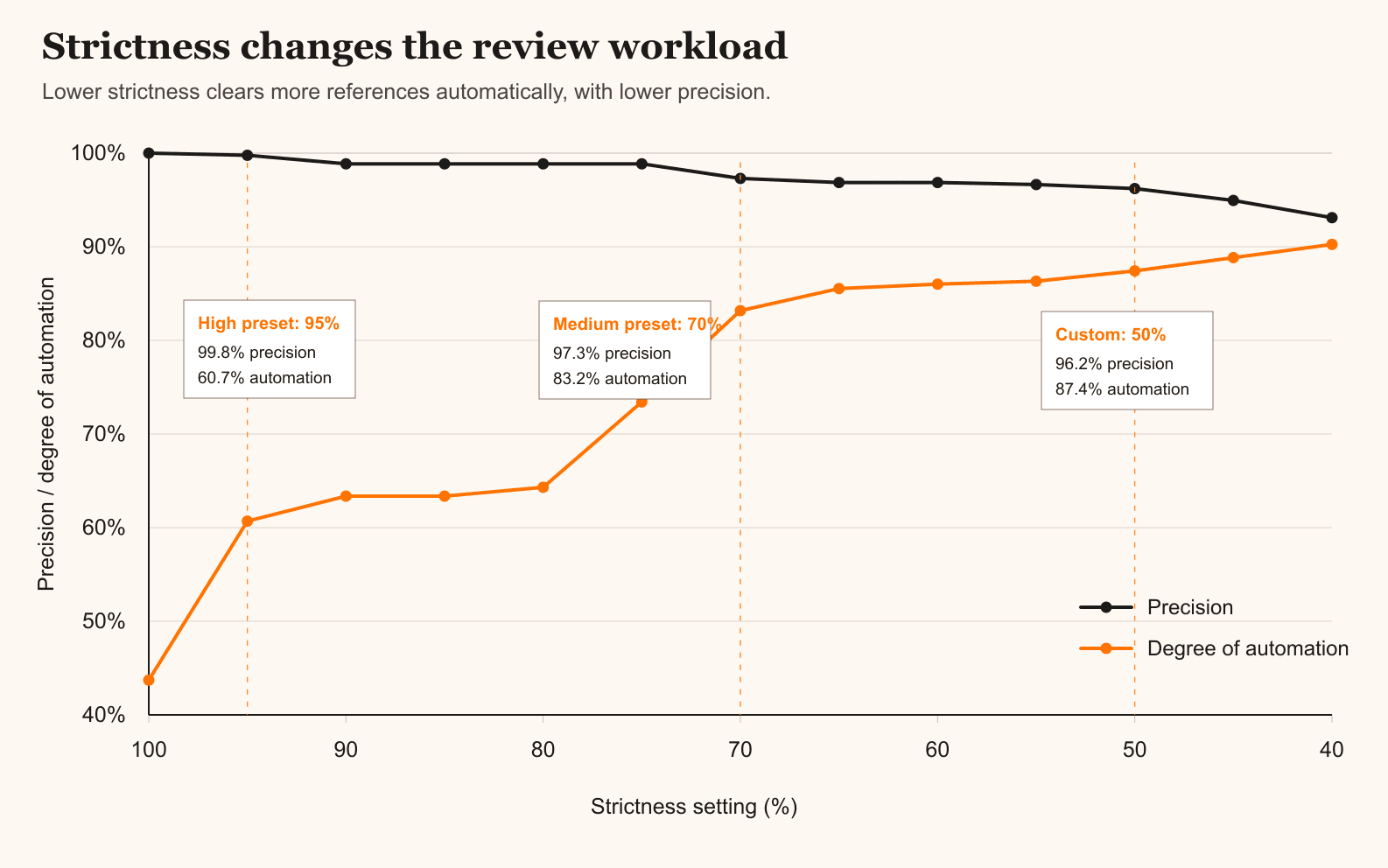
For every 100 references from the benchmark, High strictness means 39 come back orange. Medium means 17. Going from High to Medium cuts the manual review pile by more than half, with precision dropping 2.5 percentage points.
The pattern: automation rises steeply as strictness drops, while precision falls gradually. That asymmetry is why Medium is worth considering for most verification tasks.
High vs. Medium: which fits your use case
High (95%): use it when you want to find every mistake
High strictness is the right choice when you are polishing your own reference list before submission, or when every mismatch between your citations and the database is information you want to see.
At 99.8% precision and 61% automation, it will send you more references to review. Most of those orange flags will be minor: abbreviated first names, journal title variations, slightly different volume or page formatting. Those are real discrepancies — the algorithm caught them correctly. Whether they are errors in your list or quirks in the database is the call you make after reviewing them.
That last point matters: BibFox cannot determine which side is right. If the database shows "Smith John" and your list shows "John Smith," it flags the difference. It does not know whether your citation copied an error from a download or whether the database entry is inconsistently formatted. Both happen. The orange flag is the data; your review is the verdict.
Medium (70%): use it when you want to catch hallucinations and move on
Medium strictness is the default for bulk verification tasks where the primary goal is identifying references that do not exist — AI-generated fabrications, invented DOIs, sources that point nowhere.
At 97.3% precision and 83% automation, it processes most references automatically. Citations with small formatting differences are more likely to clear without an orange flag. The ones that come back orange are more likely to represent genuine problems rather than minor variations.
For a thesis review, a peer review, or a first pass on a student submission, Medium is usually the right starting point: high enough precision to catch real fabrications, low enough friction to keep the manual review pile manageable.
Custom strictness: when the presets don't fit
The presets cover most situations. Custom strictness is for cases where your list has specific characteristics that make either preset a poor fit.
The clearest example: a reference list with many URL-based sources. BibFox checks web sources, but many domains block automated access or have a misconfigured title. A reference pointing to a blocked URL cannot be verified automatically and comes back orange regardless of its actual validity. On a list heavy with web citations, this can inflate the orange pile significantly. However, you can check those warnings by hand, since eyeballing a URL is far quicker than chasing down an academic source.
Still, setting strictness to 50% can handle this, bringing automation to 87% while precision drops to 96.2%. The risk with custom low strictness is on the academic citation side. Below Medium, the algorithm is more likely to clear a fabricated academic reference that shares surface features with a real one — similar title, but wrong author and no DOI. On the benchmark data, precision drops from 99.8% at High to 96.2% at 50% and to 93.1% at 40%. That degradation is real. If your list contains AI-generated academic citations and scientific accuracy matters, stay at Medium or High. If your main concern is web sources and you do not want to can scan those quickly manually, 50% is reasonable.
Rule of thumb: do not go below Medium without a specific reason. The presets are set at the two points where the precision-automation tradeoff is most favorable. Everything below 70% gives you diminishing automation gains in exchange for accelerating precision losses.
How the algorithm makes low strictness work
The algorithm is not purely linear. Lowering strictness does not mean every reference becomes easier to clear. BibFox requires a minimum threshold of matches regardless of the strictness setting: the title must match a database entry, and at least two other core fields — author, year, DOI, journal — must also match before any automatic classification is possible. Below that floor, a reference stays unresolved or flagged, no matter how low the strictness is set.
This means the safety net holds even at 40% strictness. A fabricated reference with a plausible-sounding title but a wrong author, wrong year, and no DOI will not clear as validated. The minimum field requirement catches it. What lower strictness loosens is the tolerance for minor variation in verified fields — a different abbreviation, a slightly different rendering of the title, a name formatting difference.
The precision numbers in the benchmark reflect real cases where fabricated references shared enough surface features with genuine ones to clear at lower strictness settings. At 50%, there are about 17 such cases in 636 references. At High (95%), there is 1. The chart makes the mechanism visible: the two lines converge, but they converge slowly on the precision side because the minimum field requirement acts as a floor that does not move with the strictness dial.
One broader point about what BibFox is doing at any strictness level: it is showing you differences between your list and the database, not telling you what is correct. A database entry can be wrong. A citation you downloaded can be wrong. BibFox flags the discrepancy; the judgment is yours. High strictness means more discrepancies reach you. Medium means the smaller ones are filtered out. The underlying principle is the same at any setting.
The bottom line
The strictness setting is a tradeoff dial between manual work and precision. High (95%) finds every discrepancy, including small ones — use it when you are polishing your own list and want to catch anything that does not match. Medium (70%) clears 83% of your list automatically at 97.3% precision — use it for bulk verification where catching fabrications matters more than finding every formatting variation. Custom settings below 70% are for specific cases, not defaults; the precision loss accelerates faster than the automation gain below that point.
The asymmetry in the chart is the whole argument for Medium: automation gains are steep, precision losses are gradual. On most lists, Medium is the point where you get the most time back without meaningfully increasing your risk of missing a fabricated source.
Check your own reference list
Run BibFox on your sources and review the evidence yourself.
1. Walters, W.H., Wilder, E.I. Fabrication and errors in the bibliographic citations generated by ChatGPT. Sci Rep 13, 14045 (2023). https://doi.org/10.1038/s41598-023-41032-5